If you need to validate or delete items/products or any other records in a BIG number, it is better to run such processing, first, in CIL, second in parallel threads.
This project is to demonstrate this approach.
The whole concept is similar to what I explained in one of my previous blogpost about Multi thread parallelism and a dispatching table for finding a minimum
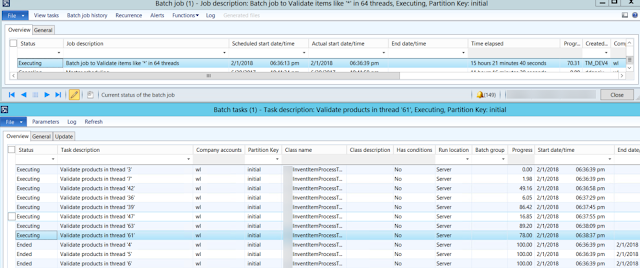
myInventItemProcessBatch class populates a special table containing RecIds to be processed and thread number they belong to.

Based on the user selection, it creates appropriate number of batch tasks that can run independently with their progress percentage.
Feel free to elaborate this project by adding new types of processing or new table to process. Also it is probably a good idea to add a new column to the table to separate different instances myInventItemProcessBatch simultaneously running in the same environment.
myInventItemProcessBatch
myInventItemProcessTask process()
This project is to demonstrate this approach.
The whole concept is similar to what I explained in one of my previous blogpost about Multi thread parallelism and a dispatching table for finding a minimum
myInventItemProcessBatch class populates a special table containing RecIds to be processed and thread number they belong to.

Based on the user selection, it creates appropriate number of batch tasks that can run independently with their progress percentage.
Feel free to elaborate this project by adding new types of processing or new table to process. Also it is probably a good idea to add a new column to the table to separate different instances myInventItemProcessBatch simultaneously running in the same environment.
myInventItemProcessBatch
private static server int64 populateItems2Process(str 20 _what2find, int _batchThreads) { myInventItemProcessTable myInventItemProcessTable; InventTable inventTable; int firstThread = 1; Counter countr; // flush all previously created items from the table delete_from myInventItemProcessTable; // insert all needed items in one shot. this part can be refactored to use Query instead insert_recordset myInventItemProcessTable (threadNum, ItemRecId, ItemId) select firstThread, RecId, ItemId from InventTable where inventTable.itemId like _what2find; // now group them in threads by simply enumerating them from 1 to N countr=1; ttsBegin; while select forUpdate myInventItemProcessTable { myInventItemProcessTable.threadNum = countr; myInventItemProcessTable.update(); countr++; if(countr > _batchThreads) { countr=1; } } ttsCommit; // return the total number of items to process select count(RecId) from myInventItemProcessTable; return myInventItemProcessTable.RecId; }
public void run() { // get all required items by their RecIds in the table and group them in threads int64 totalRecords = myInventItemProcessBatch::populateItems2Process(what2find, batchThreads); if(totalRecords) { info(strFmt("Found %1 items like '%2' to %3", totalRecords, what2find, processType)); // create number of batch tasks to parallel processing this.scheduleBatchJobs(); } else { warning(strFmt("There are no items like '%1'", what2find)); } }
...
select count(RecId) from inventTable exists join myInventItemProcessTable where myInventItemProcessTable.ItemRecId == inventTable.RecId && myInventItemProcessTable.threadNum == threadNum; // total number of lines to be processed totalLines = inventTable.reciD; // to enjoy our bored user during a few next hours // this progress just updates percentage in Batch task form progressServer = RunbaseProgress::newServerProgress(1, newGuid(), -1, DateTimeUtil::minValue()); progressServer.setTotal(totalLines); while select inventTable exists join myInventItemProcessTable where myInventItemProcessTable.ItemRecId == inventTable.RecId && myInventItemProcessTable.threadNum == threadNum { progressServer.incCount(); try { // RUN YUR LOGIC HERE //////////////////////
...

_1074.jpg)




No comments:
Post a Comment